
HOW TO: Implement SCD Type-1 Mapping in Informatica Cloud (IICS)
What is Slowly Changing Dimension (SCD) Type-1?
A Slowly Changing Dimension (SCD) Type 1 is used when it is not required to maintain history of a record in in the dimension table. The existing record is overwritten with the information from the new record when the value of one or more selected attributes changes.
The implementation of the SCD Type-1 mapping in Informatica Cloud involves
- Identifying the new record and inserting it.
- Identifying the existing record and update it with latest data if there is a change in data.
- Identifying the existing record and dropping it in the mapping if there is no change in data.
Setting up Source and Target data objects for Demonstration
For the demonstration purpose consider a flat file employees.csv as a source which provides employees information.
EMP_ID,EMP_NAME,EMP_SALARY,DEPT_ID
100,Jennifer,6000,10
101,Micheal,8000,10The data should be loaded into the target table Dim_Employees. The structure of the table is as follows.
CREATE TABLE Dim_Employees
(
Employee_Key Number(6,0),
Employee_Id Number(6,0),
Name Varchar2(20),
Salary Number(8,2),
Department_Id Number(4,0),
Checksum Varchar2(50)
)
;- Employee_Key is the surrogate key which increments the value plus one for each record inserted into the table.
- Every record has a CHECKSUM value which is unique sequence representing the data of the record. For any change in the data, the checksum value differs and helps in identifying if there is any change in the record data.
Steps to Create SCD Type-1 Mapping
The below mapping illustrates the design of SCD Type-1 implementation in Informatica Cloud Data Integration.
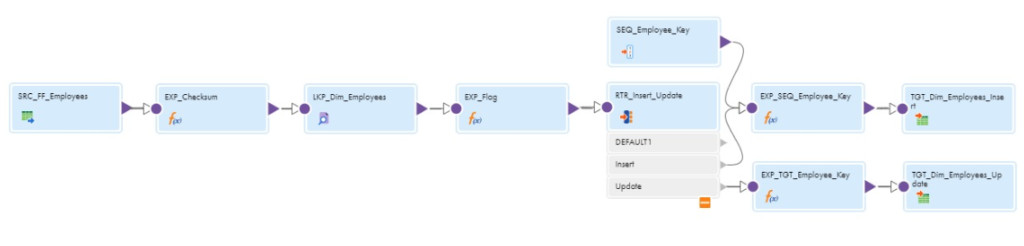
Follow below steps to create a SCD Type-1 mapping in Informatica Cloud.
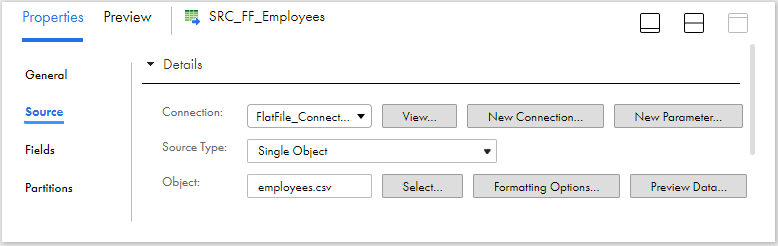
1. Select the Source Object
In the source transformation, select the employees.csv as the source object. Under Formatting Options, select the delimiter and other flat file related properties. Verify if the source fields are properly read under Fields section.
2. Create Output Fields and Checksum Value
Pass the data from source transformation to the expression transformation.
- All the fields read from flat file will be of type String. These fields should be converted to the respective data types defined as in the target dimension table.
- Calculate the Checksum value using a MD5 function by passing the required source fields in the expression transformation.
O_CHECKSUM = MD5(EMP_ID||EMP_NAME||EMP_SALARY||DEPT_ID)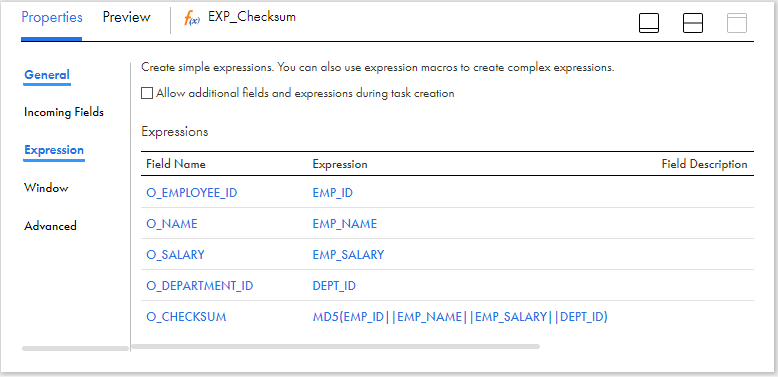
3. Look up on Target Object based on Natural Key
Pass the data to the Lookup transformation. Select the Dim_Employees table as the Lookup object. Alternatively we could write a query reading only required fields from the table as shown below.
SELECT
Employee_Key AS Lkp_Employee_Key ,
Employee_Id AS Lkp_Employee_Id ,
Checksum AS Lkp_Checksum
FROM Dim_EmployeesUnder Lookup Condition tab, select the condition based on employee id fields from source and lookup objects as shown below.

4. Flag data based on output from Lookup
Based on output from lookup transformation, the data needs to be flagged for either Insert or Update.
- If there is no matching record found for the employee_id read from source in the lookup object, flag the record for Insert.
- If there is a matching record found for the employee_id read from source in the lookup object and the data is changed, flag the record for Update.
- If there is a matching record found for the employee_id read from source in the lookup object and the data is unchanged, ignore it.
Pass the data from Lookup to an Expression transformation and create an output field Flag and assign the below field expression to flag the records.
IIF( ISNULL( Lkp_Employee_Key ), 'I',
IIF( O_Checksum != Lkp_Checksum, 'U' )
)5. Route data to different targets based on Flag
Create two output groups in the Router transformation to route the date to two different targets based on the flag value for Insert (Flag=’I’) and Update (Flag=’U’) operations as shown below.
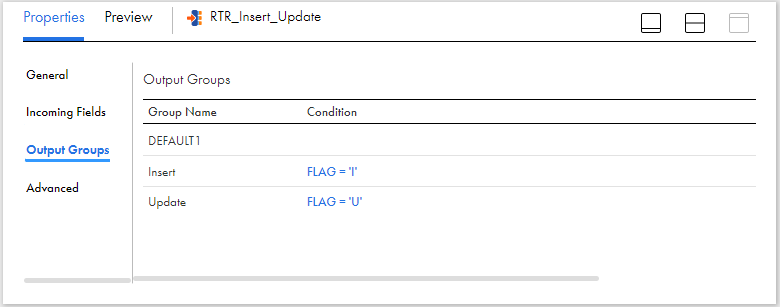
Route the data to two different expression transformation from each of the output group before mapping to target.
6. Configure Sequence Generator for generating Surrogate Keys
A Sequence Generator transformation could be used for generating surrogate keys for the target dimension table. Pass the data from sequence generator to the expression transformation linked to the Insert group of the Router transformation.
- Create an output field O_EMPLOYEE_KEY of type bigint and assign the field value as NEXTVAL coming from sequence generator.
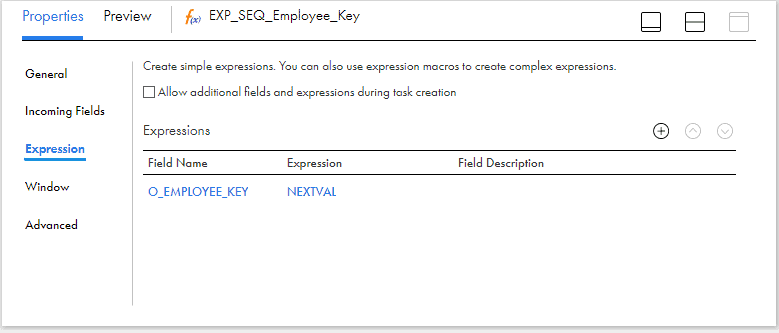
If the surrogate key value generation is handled at the database level, there is no need to use the Sequence generator transformation.
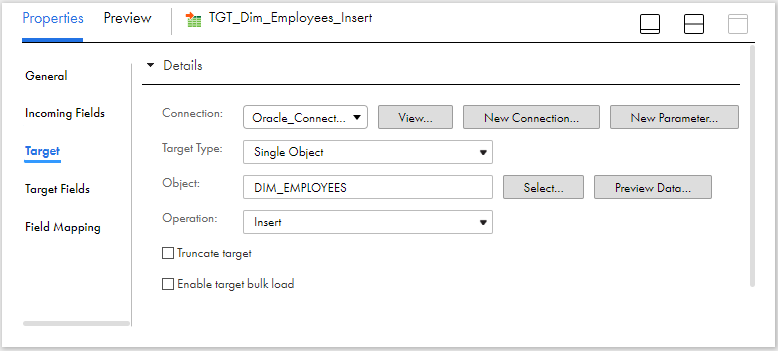
7. Configure Target for Insert Operations
Pass the data from expression to a target transformation. Select the dimension table Dim_Employees as target object with operation defined as Insert.
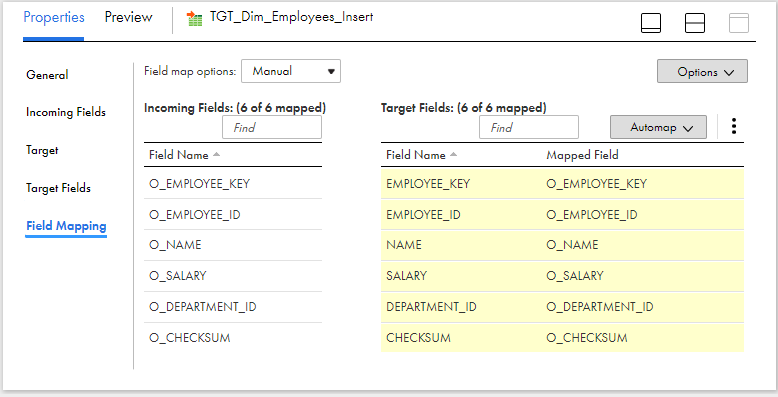
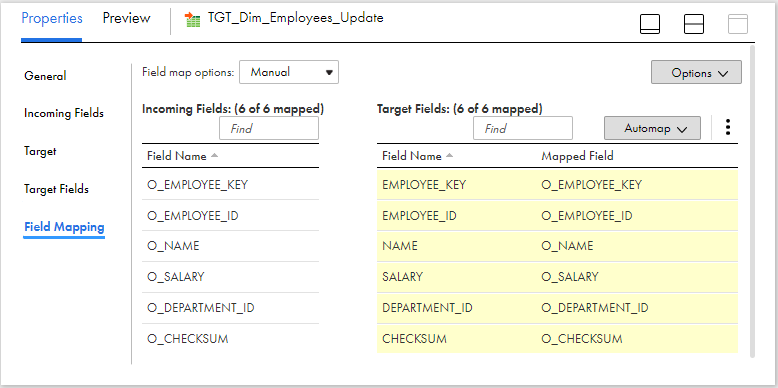
Under Field Mapping section of the target transformation, map the output fields created in the mapping to the respective target fields.
8. Configure Target for Update Operations
Pass the data from Update group of the router transformation to an expression transformation.
Create an output field O_EMPLOYEE_KEY and assign the LKP_EMPLOYEE_KEY field as the value which is read from lookup. This field is used to identify the existing record in the dimension table to update the record information.
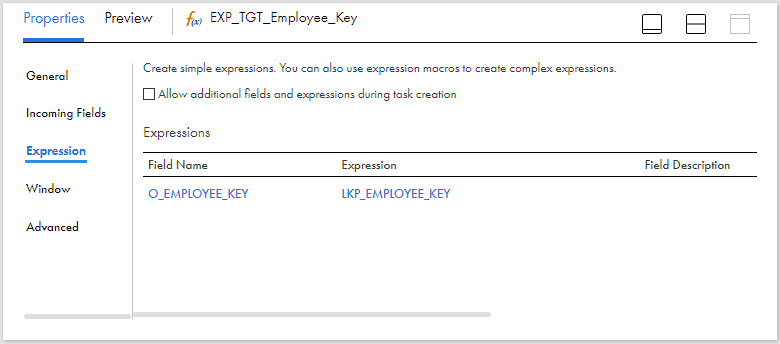
Pass the data from expression to a target transformation. Select the dimension table Dim_Employees as target object with operation defined as Update. Select the EMPLOYEE_KEY as the Update column. It is the column based on which record is identified in the target and updated.
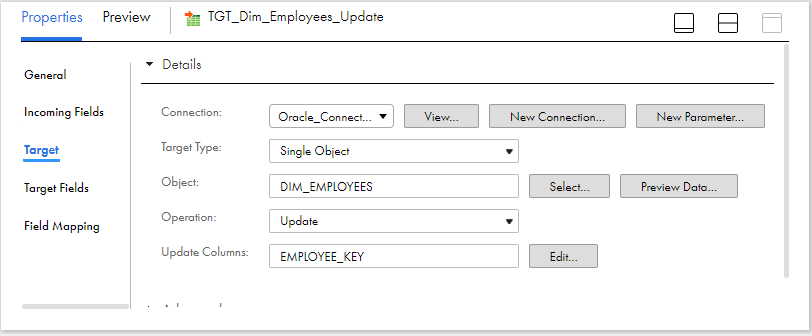
Under Field Mapping section of the target transformation, map the output fields created in the mapping to the respective target fields.
Validate, Save and trigger the mapping.
Verifying data in dimension table after the initial run
The data in the Dim_Employees table after the source data is processed is as below.

Since there is no data in the dimension table during the initial run, both the records are flagged for Insert and the data is inserted.
Verifying data in dimension table after the second run with modified source data
Consider the salary of employee with id 100 is modified to 9000 from 6000. The other employee data remains unchanged.
EMP_ID,EMP_NAME,EMP_SALARY,DEPT_ID
100,Jennifer,9000,10
101,Micheal,8000,10After the data is processed by Informatica, the data in the dimension table is as below.

The salary information of employee with Id 100 is now updated to 9000. The information of employee with id 101 remains unchanged as there is no change in data.
Conclusion
Please note the below best practices to be followed while developing the mapping.
- Follow proper naming convention while naming transformation and fields. Observe that all the output fields in the mapping demonstrated are prefixed with ‘O_’ and the lookup fields with ‘LKP_’
- If there are multiple fields in the dimension table for which change in data needs to be tracked, make sure to include a checksum field in the table as it makes easy to track the changes in the data.
- In the target transformation, limit the incoming fields by only selecting only the fields with prefix ‘O_’ using Field Rules. This eases the process of field mapping by allowing Automap feature as only required fields are allowed into the target.





0 Comments